
网络上流传着很多诸如此类 “Linux 网络一键优化脚本/配置”,并不是说这些配置不好,而是在不知道这些常用内核参数的含义和影响的前提下 xjb 调其实挺危险的,根据使用场景不同和机器配置不同,有些参数调了只是“没有帮助”,而有的调了会引起一些网络玄学故障,本文尝试结合 Linux 网络栈 ingress 和 egress 的基本架构,整理常用的一些参数的含义和相关的用途和坑点,另外,Linux 对所有可调整的内核参数,都有以下两个共同点,后文不再赘述:
- TCP 相关配置在
/proc/sys/net/ipv4/下,但 Linux 的 TCP 协议栈不分 IPV4/IPV6,所有ipv4.tcp的设置将同时影响 V6 的 TCP 连接 sysctl net.foo=bar和echo bar > /proc/sys/net/foo完全等价,但注意这两种操作都在重启后失效,如需持久化需配置/etc/sysctl.conf
Linux ingress 网络架构
Linux ingress 网络调优可以说是高性能服务器最具有挑战的部分,本文只讨论协议栈有关配置,但是作为前置知识简略介绍下述参数可能涉及到的流程和节点:
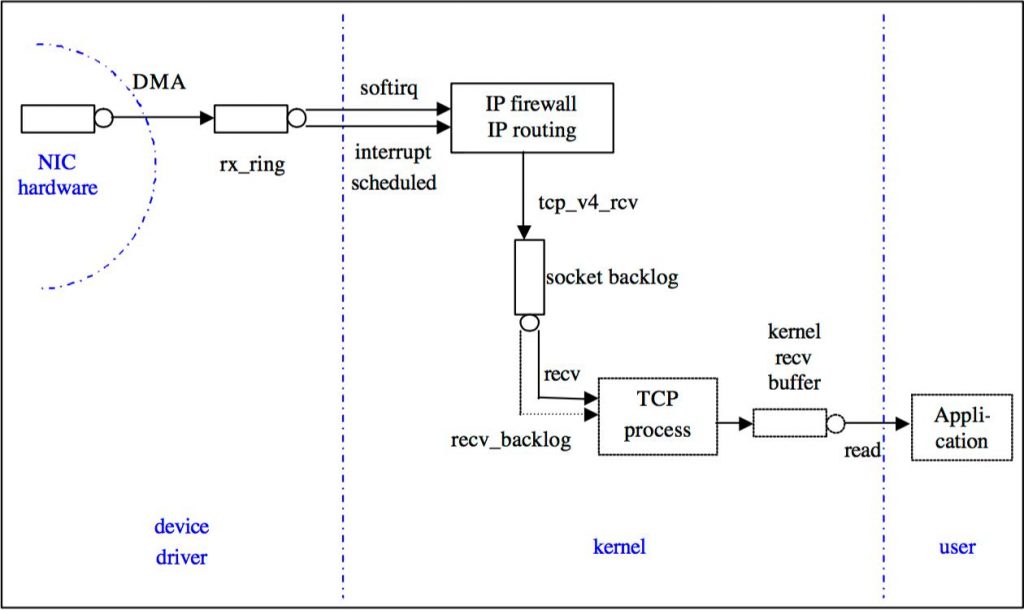
- 略去物理层和链路层处理的细节,网卡在收到包后会将帧存放在硬件的 frame buffer 上,并通过 DMA 同步到内核的一块内存(称为 ring buffer,对 ingress 称 rx_ring),
ethtool -g [nic]可以查看 ringbuffer 大小 - 在最传统的中断模式下,每个帧将产生一次硬中断,CPU 0 收到硬中断后产生一个软中断,内核切换上下文进行协议栈的处理,理论上这是延迟最低的方案,但大量的软中断会消耗 CPU 资源,导致其他外设来不及正常响应,因此可以启用中断聚合(Interrupt Coalesce),多帧产生一个中断,
ethtool -c [nic]可以查看中断聚合状态 - NAPI 是一种更先进的处理方式,NAPI 模式下网卡收到帧后会进入 polling mode 此时网卡不再产生更多的硬中断,内核的 ksoftirqd 在软中断的上下文中调用 NAPI 的 poll 函数从 ring buffer 收包,直到 rx_ring 为空或执行超过一定时间(如 ixgbe 驱动中定义超时为2个 CPU 时钟)
- 内核将收到的包复制到一块新的内存空间,组织成内核中定义的
skb数据结构,交上层处理
/proc/net/softnet_stat 记录了一些内核网络栈的状态,是网络调优的重要参考依据,但是很神奇的是内核文档没有提到,各种地方都告诉你通过 net/core/net-procfs.c 阅读它到底是什么,第 1 列是 processed 网络帧的计数,第 2 列是 dropped 计数也就是因 input_pkt_queue 不能处理导致的丢包数(和 ring buffer 满导致的丢包是两个问题),第 3 列是 NAPI 中由于 budget 或 time limit 用完而退出 net_rx_action 循环的次数,4-8 列没有意义因此全是0,第 9 列是 CPU 为了发送包而获取锁的时候有冲突的次数,第 10 列是 CPU 被其他 CPU 唤醒来处理 backlog 数据的次数,第 11 列是触发 flow_limit 限制的次数,需要注意,本文的描述忽略了很多实现中的细节,没有讨论 NAPI 的配置项,也没有讨论 RSS / RPS 所带来的 CPU 分配等问题,较为完整的基于源码讨论 Linux ingress 可以参见 https://arthurchiao.github.io/blog/tuning-stack-rx-zh/。
另外有趣的一点是,根据一篇研究报告: Evaluating and Optimizing I/O Virtualization in Kernel-based Virtual Machine (KVM),在 KVM 的模拟网卡(e1000 等,不包括 virtio)下打开 NAPI 反而会导致性能有明显的下降,这也印证本文开头的观点,调优是一件因地制宜的事情,生搬硬套脚本可能适得其反。
backlog 队列和缓存相关
net.ipv4.tcp_rmem
本参数中的 rmem / wmem 即是 socket buffer 也就是内核源码中常见的 skb,也是上图描述的 kernel recv buffer。
此参数分为三列,表示最低/默认/最大,内核会根据可用内存大小动态进行调整,rmem 为收包缓冲,默认值为:net.ipv4.tcp_rmem = 4096 87380 6291456
- 第一列表示每个 TCP socket 的最小收包缓冲,这个值用于系统内存紧张时保证最低限度的连接建立,注意指定过
SO_RCVBUF的 socket 不受此参数限制。在 Linux2.4+ 中,此数值默认为4KB,(On Linux 2.4, the default value is 4 kB, lowered to PAGE_SIZE bytes in low-memory systems.) 此处 low memory 指 32bit 系统中的概念,详见 https://support.symantec.com/us/en/article.tech244351.html,64bit 系统可以认为 low memory 和 high memory 都为 total memory。 - 第二列表示每个 TCP socket 的默认收包缓冲,此数值将会覆盖全局参数
net.core.rmem_default(定义了所有协议的接收缓冲),Linux2.4+ 默认值为87380,32位系统为43689。 - 第三列表示每个 TCP socket 最大收包缓冲,注意指定过
SO_RCVBUF的 socket 不受此参数限制。此数值 不覆盖 全局参数net.core.rmem_max,此数值的默认值由max(87380, min(4 MB, tcp_mem[1]*PAGE_SIZE/128))得到,Linux2.4+ 上为87380*2,32位系统为87380。
net.ipv4.tcp_wmem
默认值为: net.ipv4.tcp_wmem = 4096 16384 4194304,格式同 rmem,wmem 为发包缓冲,各列含义和注意事项也和 rmem 一致,以下只列出区别:
- 第一列,指定过
SO_SNDBUF的 socket 不受此参数限制。 - 第二列,此数值会覆盖全局参数
net.core.wmem_default(定义所有协议的发送缓冲),Linux2.4+ 默认值为16KB, - 第三列,此数值 不覆盖 全局参数
net.core.wmem_max,此数值的默认值由max(65536, min(4 MB, tcp_mem[1]*PAGE_SIZE/128))得到,Linux2.4+ 上为128KB
net.core.rmem & net.core.wmem
即上述定义所有协议收发缓冲的全局参数。buffer 不是越大越好,过大的 buffer 容易影响拥塞控制算法对延迟的估测,一个经验公式是Buffer size = Bandwidth (bits/s) * RTT (seconds)(然并卵,要是 buffer 这么好预估就不会有 bufferbloat 问题困扰 TCP 几十年了)
需注意上述几个 buffer 不应设置得过大,当上层处理能力遇到瓶颈时,尤其是当 net.core.somaxconn 也设置的较大时可能消耗较多内存、增加收发延迟,而不能带来吞吐量的提高。
net.core.netdev_max_backlog
netdev backlog 是上图中的 recv_backlog,所有网络协议栈的收包队列,网卡收到的所有报文都在 netdev backlog 队列中等待软中断处理,和中断频率一起影响收包速度从而影响收包带宽,以 netdev_backlog=300, 中断频率=100HZ 为例:
300 * 100 = 30 000 packets HZ(Timeslice freq) packets/s 30 000 * 1000 = 30 M packets average (Bytes/packet) throughput Bytes/s
如先前所述,可以通过 /proc/net/softnet_stat 的第二列来验证, 如果第二列有计数, 则说明出现过 backlog 不足导致丢包,但有可能这个参数实际驱动没有调用到,分析丢包问题时如果需要调整此参数,需要结合具体驱动实现。
net.ipv4.tcp_max_syn_backlog & net.ipv4.tcp_syncookies
tcp_max_syn_backlog 是内核保持的未被 ACK 的 SYN 包最大队列长度,超过这个数值后,多余的请求会被丢弃。对于服务器而言默认值不够大(通常为128),高并发服务有必要将netdev_max_backlog和此参数调整到1000以上。
注意 tcp_syncookies 启用时,此时实际上没有逻辑上的队列长度,backlog 设置将被忽略,顺带一提 syncookie 是一个出于对现实的妥协而严重违反 TCP 协议的设计,会造成 TCP option 不可用,且实现上通过计算 hash 避免维护半开连接也是一种 tradeoff 而非万金油,勿听信所谓“安全优化教程”而无脑开启。
冷知识:在2.6.20之前的内核上,需要满足 TCP_SYNQ_HSIZE * 16 <= tcp_max_syn_backlog 而 TCP_SYNQ_HSIZE 需要重新编译内核生效,2.60.20之后的内核去掉了这个硬编码改为动态设置。
net.core.dev_weight & net.core.netdev_budget
前者是 NAPI polling 时每核每次软中断最多处理的帧数量,后者是所有网卡每次软中断最多处理的总帧数量,一次 polling mode 过长可能导致延迟的波动等问题
net.core.somaxconn
somaxconn 是一个 socket 上等待应用程序 accept() 的最大队列长度,默认值通常为128。
在一个 socket 进行 listen(int sockfd, int backlog) 时需要指定 backlog 值作为参数,如果这个 backlog 值大于 somaxconn 的值,最大队列长度将以 somaxconn 为准,多余的连接请求将被放弃,此时客户端可能收到一个 ECONNREFUSED 或忽略此连接并重传。
注意此 backlog 不是 tcp_max_syn_backlog,此 backlog 指定的是完全建立 ESTABLISH 状态但还未被应用程序 accept() 的连接数,而tcp_max_syn_backlog 指定的是未完成握手不在 ESTABLISH 的等待队列长度,二者存在区别的原因是连接建立和 accept() 调用没有本质关联。
将此参数调大可以一定程度上避免高并发服务遇到突发流量导致丢包,但是如果应用程序处理速度跟不上收包速度,调大 somaxconn 是没有意义的,只会导致 client 端虽然不会因为拥塞而被断开连接,但是请求依旧没有被处理,某些情况下甚至会造成反效果(如负载均衡器后的一台后端遇到瓶颈无法处理更多请求时,应该快速将连接断开使客户端重连到其他后端,而不是将请求堆积在这台满载的后端上)
本节参考:
http://man7.org/linux/man-pages/man7/tcp.7.html
http://veithen.io/2014/01/01/how-tcp-backlog-works-in-linux.html
http://man7.org/linux/man-pages/man2/listen.2.html
TIME_WAIT 相关
TIME_WAIT 状态原本是为避免连接没有可靠断开而和后续新建的连接的数据混淆,TIME_WAIT 中的 peer 会给所有来包回 RST,对于 Windows,TIME_WAIT 状态持续的 2MSL 可以通过注册表配置,而 Linux 则是写死在内核源码里的60秒。
对于会主动关闭请求的服务端(典型应用:non-keepalive HTTP,服务端发送所有数据后直接关闭连接),实际上并不会出现在主动关闭之后再向那个客户端发包的情况,所以 TIME_WAIT 会出现在服务端的80端口上,正常情况下,由于客户端的(source IP, source port)二元组在短时间内几乎不会重复,因此这个 TIME_WAIT 的累积基本不会影响后续连接的建立,有些例外情况如压力测试且客户端只有少数几台机器的时候,连接建立和断开过快会导致客户端二元组在短时间内循环,若此时服务器端口上的 socket 仍处于 TIME_WAIT 状态则会无法建立连接 。
但在反向代理中,TIME_WAIT 问题则会非常明显,如 nginx 默认行为下会对于 client 传来的每一个 request 都向 upstream server 打开一个新连接,高 QPS 的反向代理将会快速积累 TIME_WAIT 状态的 socket,直到没有可用的本地端口,无法继续向 upstream 打开连接,此时服务将不可用。
实践中,服务端使用 RST 关闭连接可以避免服务端积累 TIME_WAIT,但更优的设计是服务端告知客户端什么时候应该关闭连接,然后由客户端主动关闭。
net.ipv4.tcp_max_tw_buckets
此数值定义系统在同一时间最多能有多少 TIME_WAIT 状态,当超过这个值时,系统会直接删掉这个 socket 而不会留下 TIME_WAIT 的状态。
net.ipv4.tcp_tw_reuse & net.ipv4.tcp_tw_recycle
这两个选项都依赖 TCP 时间戳,即 net.ipv4.tcp_timestamps = 1,
tw_reuse 会根据 TCP 时间戳决定是否复用 TIME_WAIT socket,在 tw_buckets 满的时候,会根据 TCP 时间戳决定是否复用 TIME WAIT socket,选取一个已经持续1秒以上的连接,复用这个五元组,这个选项只对客户端(反代服务器连接 upstream 时也可认为是客户端)有效。
tw_recycle 使用对 RTT 及其方差估算 RTO (retransmission timeout),会导致内核丢弃收到的时间戳不严格递增的包,此参数存在严重问题,将会影响本机和 NAT 后主机的通信,另一方面为了防止对 NAT 后主机的追踪,4.10 内核开始 TCP 的时间戳增加了随机的 offset(ref: https://lwn.net/Articles/708021/),也就是无论是否 NAT,时间戳都将不是严格递增的,这和 tw_recycle 产生了冲突,因此 4.12 内核中此参数已经永久废弃,不再存在这个配置项,因此也不再存在继续纠结这个选项要不要开的必要。
net.ipv4.ip_local_port_range
TCP 建立连接时 client 会随机从该参数定义的端口范围中选择一个作为源端口,这个端口范围一般被称作临时端口(ephemeral ports)或动态端口(dynamic ports),更具体的说,是以下几种情况之一会分配一个临时端口,如果无可用临时端口,下述系统调用将返回错误。因此,当所有临时端口都处于 TIME WAIT 状态时,系统将无法对外发起连接:
- bind() 调用时端口号指定为0
- 在一个未 bind 的端口上使用 connect() 调用
- 在一个未 bind 的 TCP 端口上使用 listen() 调用
- 在一个未 bind 的 UDP 端口上使用 sendto() 调用
此参数默认值通常为 net.ipv4.ip_local_port_range = 32768 60999(部分发行版默认的最大临时端口为61000),由于 TCP/IP 协议中低于1024的端口号被保留作为熟知端口监听使用,因此最小临时端口必须大于1024(推荐大于4096),最大临时端口可以为 TCP/IP 最大端口号65535。
把此参数列在这一节是因为调大此参数可以一定程度上缓解 TIME WAIT 状态 socket 堆积导致无法对外建立连接的问题(实际上也经常这么干),但是不是根本性的解决途径。
本节参考:
http://www.serverframework.com/asynchronousevents/2011/01/time-wait-and-its-design-implications-for-protocols-and-scalable-servers.html
http://lxr.linux.no/linux+v3.2.8/Documentation/networking/ip-sysctl.txt#L464
https://vincent.bernat.im/en/blog/2014-tcp-time-wait-state-linux
流控和拥塞控制相关
众所周知 TCP 是一个设计于几十年前的原始协议,最初的 TCP 是没有任何控制的,直到计算机和交换设备的性能随着摩尔定律的增长越来越快,TCP 网络出现了拥堵导致瘫痪,1988年 TCP 加入了最初的拥塞控制机制,
net.ipv4.tcp_congestion_control
TCP 的拥塞控制算法理论非常复杂,大体上说,有基于延迟改变、丢包反馈几个设计思路:
- 基于丢包反馈(Reno):就像计算机网络课本里学到的 AIMD(线性增乘性减),分为 cwnd 指数增长的慢启动阶段、cwnd 超过 ssthresh 后线性增加的拥塞避免阶段、收到 dup ACK 后 cwnd 折半进入快速恢复阶段,如果快速恢复超时则进入慢启动,以此循环
- 基于丢包反馈的改进型(STCP、BIC、Cubic):基本都通过设定一些参数改进乘性减阶段和快速恢复速度,避免流量和 Reno 一样出现锯齿形波动,以提升高带宽下的链路利用率,如目前 Linux 内核默认使用的 Cubic 就是使用了三次函数代替简单二分而得名
- 基于延迟变化(Vegas 和 Westwood ):Vegas 通过 RTT 变化判断是否出现拥塞,RTT 增加则 cwnd 减少,RTT 减少则 cwnd 增加,这种算法在与其他算法共用链路时会显得过于“绅士”而吃亏;Westwood 则通过 ACK 达到率判断链路利用率上限,适用于无线网络但无法区分网络拥塞还是无线抖动而普适性较低
- 基于主动探测(BBR):BBR 旨在通过主动探测消除 bufferbloat 对上述各大算法的误判影响,关于 bbr 的故事,可以阅读本节参考中 dog250 博主其他文章
关于各个拥塞控制算法的细节和优劣,可以阅读本节参考1,这里我不展开也没有能力展开讨论 bufferbloat 的产生和对抗他的理论推导,但是结论上说,拥塞控制是一个很复杂而目前都没有最优解的问题。但是对于终端用户而言,讨论 net.ipv4.tcp_congestion_control 基本是在讨论“要不要用 bbr”,就结论而言,不要无脑推崇 bbr,bbr 并不适合任何网络环境。
设计上 bbr 配合了 http/2 的大流传输特点,因此拥有启动快抖动小等优点,且由于 bbr 并不以丢包为减小窗口的判断依据,bbr 能很好的对付大带宽传输中的少量丢包;但是在总可用带宽较小时,bbr 的降速不够迅速准确,自身带宽利用率低还会影响同一网络下的其他流。因此 bbr 适合丢包率不太高(bbr 算法硬编码了一个丢包率20%,超过门限会导致 bbr 自行降速)的长胖管道(Long-Fat Network,指延迟较高且带宽较大)
net.core.default_qdisc
qdisc (queue disciplines) 其实是 egress traffic control 和 qos 相关的问题而不是 TCP 的拥塞控制问题,下图是一个简化版的 egress 架构,
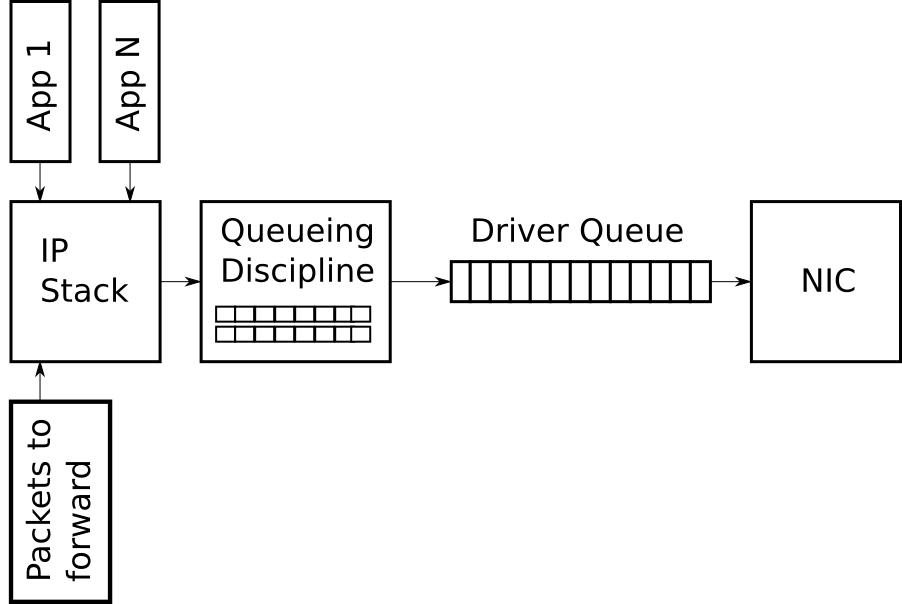
网络设备或多或少都有 buffer,初衷是以增大少许延迟来避免丢包,然而 buffer 的存在所导致的延迟可能干扰 TCP 对链接质量的判断,buffer 最终被塞满,丢包不可避免,反而新引入了延迟波动问题,这一现象被称为 bufferbloat,网络开发者们一直致力于研究更好的 qdisc 算法,避免 buffer bloat 带来的影响,这些有基于分类的算法也有无分类算法,其中分类算法最简单的实现有 prio HTB CBQ 等,无分类有 pfifo pfifo_fast tbf 等,针对 bufferbloat 的改进算法有 tail-drop red blue codel 等,其中:
- pfifo_fast 是众多发行版的默认参数,它实现简单,很多网卡可以 offload 而减少 CPU 开销,但它默认队列过长很容易引起 bufferbloat,不能识别网络流可能导致部分流被饿死
- fq (fair queue) 针对了 pfifo 及其衍生算法的缺点,它将每个 socket 的数据称为一个流,以流为单位进行隔离,分别进行 pacing 以期望得到公平发送的效果
- codel 是一种针对 bufferbloat 设计的算法,使用 BQL 动态控制 buffer 大小,自动区分“好流”和“坏流”,fq_codel 对非常小的流进行了优化避免饿死问题
- cake 是 codel / fq_codel 的后继者,内建 HTB 算法进行流量整形而克服了原版 HTB 难以配置的问题,号称能做 fq_codel 能做的一切且比 fq_codel 做得更好,在 4.19 中被引入内核
一个比较笼统但通俗的解释是:终端设备(内容的生产者或最终接收者,而不是转发设备)的 qdisc 更适合 fq,转发设备更适合 codel 及其衍生算法,根据一些不完全的实践,bbr 配合 fq_codel 工作的很好,cake 理论上可作为 fq_codel 的替代,但是目前没有太多实践资料可供参考。
net.ipv4.tcp_window_scaling
window scaling 是一个布尔值,决定是否启用 RFC 1323 TCP Extensions for Long-Delay Paths (实际已经被 7323 替代,不过内核文档中写的依然还是 1323)定义的增大接收窗口,内核自 2.6.8 版本后将其默认设为启用。
在讨论 bbr 的时候我们提到过长胖管道,这里更加详细的讨论一下。定义带宽延迟乘积(bandwidth-delay product) BDP = bandwidth * RTT ,代表已经发送但是对端尚未接收的数据量,可知当带宽和延迟都很大时,某一时刻在传输中的数据量也会很大(在 RFC 1323 的前身 1072 中定义这个值显著大于 10^5 bit 或 12500 byte 为长胖网络,但是需要考虑这个定义的时代局限性,现在几乎没有什么网络不满足这个标准)。由于 TCP 在默认情况下使用 16 bit 字段定义窗口大小,则滑动窗口最大为 2^16 = 65556 = 64 KiB;又因为 TCP 在一个 RTT 内最多接受一个完整的接收窗口大小的数据,意味着如果 BDP 超过了 64 KiB,则 TCP 无法有效利用所有链路带宽。
为了解决这个问题,TCP 将 header 中的2个字节用于移位计数,最大可以使用14位作为移位计数值,使得接收窗口可以大至 (2^16-1)*2^14 = 1073725440 byte ≈ 1 GiB,意味着在上千毫秒延迟的卫星链路中,也可以以超过1Mbps的速度进行通信。
本节参考:
https://www.bufferbloat.net/projects/bloat/wiki/What_can_I_do_about_Bufferbloat/
https://www.ietf.org/proceedings/88/slides/slides-88-tcpm-9.pdf
https://blog.csdn.net/dog250/article/details/72849893
https://www.ibm.com/support/knowledgecenter/en/ssw_aix_71/performance/rfc1323_tunable.html
nf_conntrack 相关
见先前的讨论:https://www.starduster.me/2019/07/05/nf-conntrack-tuning/
TCP keepalive 相关
简单的说,TCP keepalive 是建立 TCP 连接是分配一个计数器,当计数器归零时,发送一个空 ACK(dup ack 是被允许的),主要有两大目的:
- 探测对端存活(避免对端因为断电等突发故障没有发出连接中断通知,而服务器一直傻傻的 hold 连接直到 ESTABLISH 超时)
- 避免网络 idle 超时(比如 lvs、NAT 硬件、代理等流表过期)
相关内核参数主要有:
net.ipv4.tcp_keepalive_time
最大闲置时间,从最后一个 data packet(空 ACK 不算 data)之后多长时间开始发送探测包,单位是秒
net.ipv4.tcp_keepalive_intvl
发送探测包的时间间隔,在此期间连接上传输了任何内容都不影响探测的发送,单位是秒
net.ipv4.tcp_keepalive_probes
最大失败次数,超过此值后将通知应用层连接失效
- 需要注意 TCP keepalive 不是 Linux 系统的默认行为,需要显式指定 socket option
so_keepalive
一个比较有意思的是,由于 TCP keepalive 凭空增加了需要传输的数据量,可能造成一些意想不到的坑。贵司曾经遇到过一个这样的诡异问题,某个大规模业务集群(集群内机器之间有大量互联),如果启动服务-打开防火墙接受外部请求的这个时间间隔较长,会出现集群内连接异常断开的现象。经查,由于启动服务进程是通过任务下发批量执行的,所有机器上的服务进程在几乎同时启动,并由于防火墙没开外网,所有服务同时进入空闲状态,如果空闲达到 TCP keepalive 的闲置时间,则集群内机器的互联连接会在几乎同一时间开始发送 keepalive 报文,造成了类似互相 DDOS 的效果,大量空 ACK 报文瞬间塞满了网卡的 ringbuffer 并造成丢包,严重时 TCP 连接就会断开。解决这个问题的方式也很简单,应用层增加随机心跳,避免所有机器同时触发 keepalive 即可避免,另一方面也可以通过调大网卡 ringbuffer 提高服务器对突发流量的承受力。
本节参考:
http://tldp.org/HOWTO/TCP-Keepalive-HOWTO/overview.html
https://tools.ietf.org/html/rfc1122#page-101
其他
最后附上一些自用的参考值:
# net.ipv4.tcp_tw_recycle=0 net.ipv4.tcp_tw_reuse = 1 net.ipv4.ip_local_port_range = 1024 65535 net.ipv4.tcp_rmem = 16384 262144 8388608 net.ipv4.tcp_wmem = 32768 524288 16777216 net.core.somaxconn = 8192 net.core.rmem_max = 16777216 net.core.wmem_max = 16777216 net.core.wmem_default = 2097152 net.ipv4.tcp_max_tw_buckets = 5000 net.ipv4.tcp_max_syn_backlog = 10240 net.core.netdev_max_backlog = 10240 net.netfilter.nf_conntrack_max = 1000000 net.ipv4.netfilter.ip_conntrack_tcp_timeout_established = 7200 net.core.default_qdisc = fq_codel net.ipv4.tcp_congestion_control = bbr net.ipv4.tcp_slow_start_after_idle = 0
实际上 Linux 网络调优远不止内核参数一个方面,网卡配置、驱动相关,包括交换机配置都有可能涉及,不过那就是另一个故事了,有机会的话(咕咕咕)会抽时间整理一下包括 RSS / RPS / busy poll 等问题、另一个视角出发的网络调优笔记。
本文链接:https://www.starduster.me/2020/03/02/linux-network-tuning-kernel-parameter/
本站基于 Creactive Commons BY-NC-SA 4.0 License 允许并欢迎您在注明来源和非商业使用前提下自由地对本文进行复制、分享或基于本文进行创作。
请注意:受限于笔者水平,本站内容可能存在主观臆断或事实错误,文中信息也可能因时间推移而不再准确,在此提醒读者结合自身判断谨慎地采纳。
Permalink
Permalink
linux -网络socket – TCP
Permalink
学习了,感谢大佬。