
在内核中,连接跟踪表是一个二维数组结构的哈希表(hash table),哈希表的大小记作HASHSIZE,哈希表的每一项(hash table entry)称作bucket,因此哈希表中有HASHSIZE个bucket存在,每个bucket包含一个链表(linked list),每个链表能够存放若干个conntrack条目(bucket size)。需要明确的是,nf_conntrack 模块并不是所有 Linux 内核都会加载,最常见的导致加载该模块的原因是使用了 iptables、lvs 等内核态 NAT/防火墙导致内核需要对连接表进行追踪,iptable_nat、ip_vs 等多个内核模块都依赖 nf_conntrack, 但是 nf_conntrack 的存在会影响高并发下的内核收包性能。
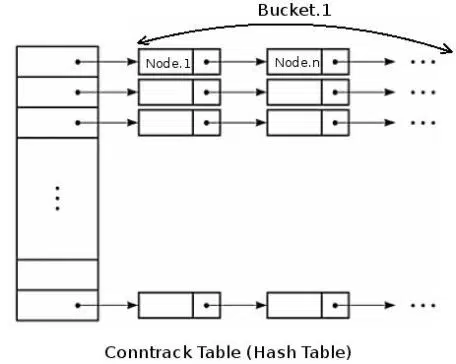
对于一个新收到的数据包,内核使用如下步骤判断其是否属于一个已有连接:
- 内核提取此数据包信息(源目IP,port,协议号)进行hash计算得到一个hash值,在哈希表中以此hash值做索引,索引结果为数据包所属的bucket(链表)。这一步hash计算时间固定并且很短
- 遍历hash得到的bucket,查找是否有匹配的conntrack条目。这一步是比较耗时的操作,
bucket size越大,遍历时间越长
bucket_size 和 hashsize 的关系
根据上面对哈希表的解释,系统最大允许连接跟踪数CONNTRACK_MAX = 连接跟踪表大小(HASHSIZE) * Bucket大小(bucket size)。从连接跟踪表获取bucket是hash操作时间很短,而遍历bucket相对费时,因此为了conntrack性能考虑,bucket size越小越好,默认为8或者4
nf_conntrack_max – INTEGER Size of connection tracking table. Default value is nf_conntrack_buckets value * 4.
net.netfilter.nf_conntrack_buckets 即是 /sys/module/nf_conntrack/parameters/hashsize
同时设定了 conntrack_max 和 hashsize 时,bucket_size会调整为其比值:
# sysctl net.netfilter.nf_conntrack_buckets
net.netfilter.nf_conntrack_buckets = 65536
# sysctl net.netfilter.nf_conntrack_max
net.netfilter.nf_conntrack_max = 100000000
# echo "100000000 65536"| awk '{printf "%.2f\n",$1/$2}'
1525.88
计算 conntrack 消耗的内存
计算方法:
total_mem_used(bytes) = CONNTRACK_MAX * sizeof(struct ip_conntrack) + HASHSIZE * sizeof(struct list_head)
样例代码:
import ctypes #不同系统可能不一样,ldconfig -v | grep conntrack 获取对应版本 LIBNETFILTER_CONNTRACK = 'libnetfilter_conntrack.so.3.5.0' nfct = ctypes.CDLL(LIBNETFILTER_CONNTRACK) print 'sizeof(struct nf_conntrack):', nfct.nfct_maxsize() print 'sizeof(struct list_head):', ctypes.sizeof(ctypes.c_void_p) * 2
在上述机器(hashsize=65536, conntrack_max=100000000)上运行结果:
根据上述算式得出线上配置内存的理论消耗:100000000 * 328 +65536 * 16 bytes,主要由第一项组成
相关问题和处理
最近遇到了一个 nf_conntrack 相关的问题,背景是:近期贵组 LB 上线了一个新的集群,在只有接入项目较少的情况下,出现了 CPU 异常压力过大的问题,perf 发现大量 CPU 消耗在 nf_conntrack_find_get 上:
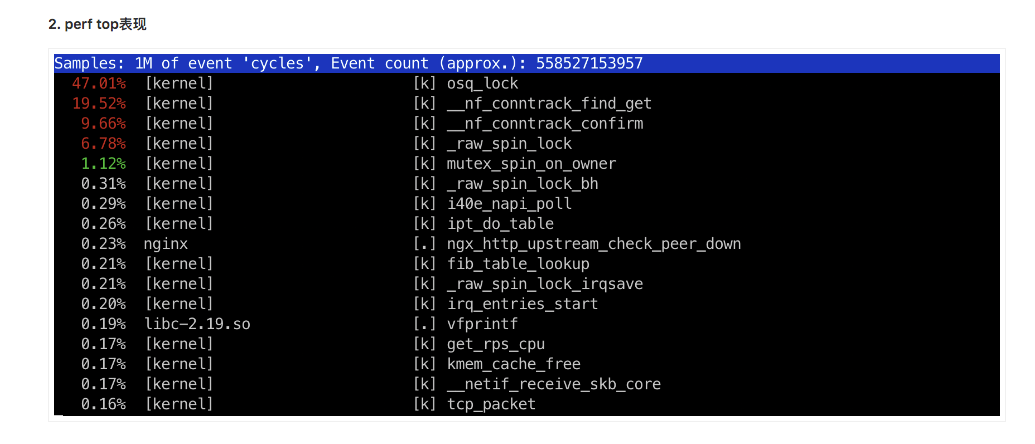
经查,nf_conntrack bucket hashsize 过小,导致 bucket size 大,查表效率差,调整前 /sys/module/nf_conntrack/parameters/hashsize 为16384,经上述算法计算 bucket size 高达6000+,将 hashsize 调整为524288后比值为100量级。
echo "`sysctl -n net.netfilter.nf_conntrack_max` 16384"| awk '{printf "%.2f\n",$1/$2}'
6103.52
echo "`sysctl -n net.netfilter.nf_conntrack_max` `sysctl -n net.netfilter.nf_conntrack_buckets`"| awk '{printf "%.2f\n",$1/$2}'
190.73
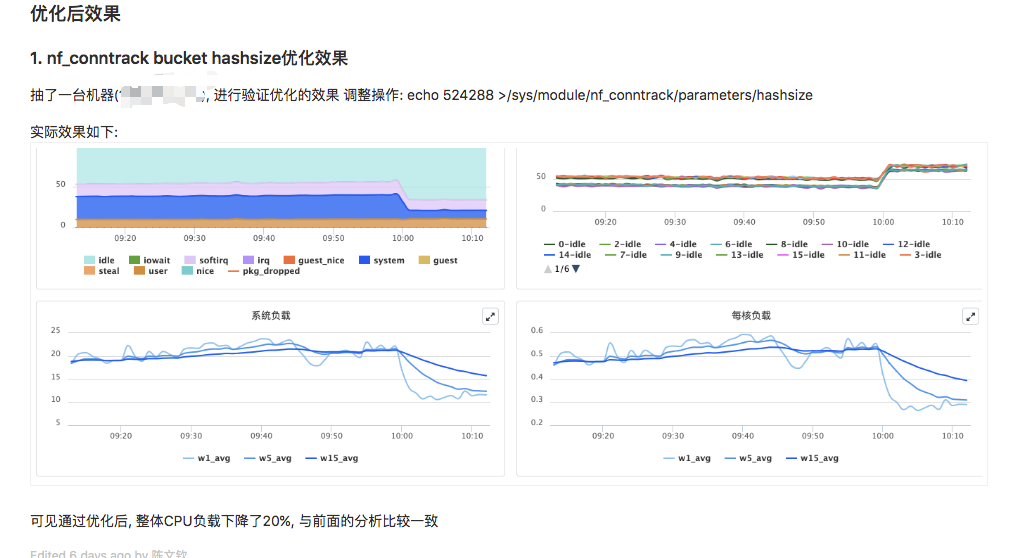
出现这么低级的配置问题,贵司环境初始化确实还是挺一把梭的···
本文链接:https://www.starduster.me/2019/07/05/nf-conntrack-tuning/
本站基于 Creactive Commons BY-NC-SA 4.0 License 允许并欢迎您在注明来源和非商业使用前提下自由地对本文进行复制、分享或基于本文进行创作。
请注意:受限于笔者水平,本站内容可能存在主观臆断或事实错误,文中信息也可能因时间推移而不再准确,在此提醒读者结合自身判断谨慎地采纳。
Permalink
其实也是 Linux 的默认值太小了(太考虑 low-end 环境,而没有那么考虑服务器环境)
Permalink
Permalink