
TL; DR:本文简要介绍了 IPV6 自动配置的基本概念和原理,并讨论了在 Linux 下自动配置(aka. SLAAC)原理和坑点,其中:
- 启用 IPV6 SLAAC 并允许内核自动添加 IPV6 默认路由需要使
net.ipv6.conf.{iface}.autoconf = 1且net.ipv6.conf.{iface}.accept_ra = 1 - 如果启用了
net.ipv6.conf.{iface}.forwarding,则对应网卡接口accept_ra需要为 2 - 上述 iface 既可以是 default/all,也可以是具体某个网卡接口,但是需要特别注意,对于部分 IPV6 配置项,仅修改
net.ipv6.conf.all时不会应用到全部网卡接口,使用时请确认所需的网卡接口上配置正确。 - 另外在部分发行版中可能修改
accept_ra实际不生效,系统可能出现预期外行为(无法自动获取的地址和路由,或配置为不需要 SLAAC 时系统仍会进行配置等),此时可检查系统中是否存在其他网络管理工具如 systemd-networkd 和 netplan 造成了影响。
背景:IPV6 和 SLAAC
讨论这个问题前需要先梳理几个 IPV6 有关的协议之间的关系,IPV6 基于功能强大的 ICMPv6,实现了“即插即用”的从地址到网关自动配置,当然如果愿意的话 IPV4 中的传统的配置方式,包括但不限于编辑 interface 文件、使用 iprouote2 等进行手动的地址和网关管理的方式,在 IPV6 中也可以使用的:
- NDP:基于 ICMPv6 的一种 ARP 的替代协议,是 IPV6 自动配置的基础。
- RS 和 RA:router solicitation 和 router advertisement,顾名思义是请求和下发路由器信息,通过 IPV6 组播实现,实际可下发的信息包括 IPV6 前缀、MTU、默认网关、有效时间等。
- SLAAC:基于 NDP 的路由宣告,客户端可实现零配置接入 IPV6 网络,其中地址前缀通过 RA 获得,后缀通过 EUI64 从 MAC 地址直接生成(如果启用了 RFC 4941 SLAAC 隐私扩展则会在对外发起连接时使用临时生成的地址,此为后话),默认路由通过 RA 下发。
正常情况下,如果内核参数和网络环境配置正确,ip -6 route 可见一条 default via fe80::xxxx dev iface proto ra 的默认路由表项,

明确这些基本概念,接下来继续讨论 Linux 中 SLAAC 的实际配置和行为。
梳理:自动配置和内核参数
之所以有本文,是因为在实际使用中遇到了这样的现象:已知二层存在响应 NDP 的 IPV6 网关,子网内两台服务器都启用了 autoconf,其中一台 A 可以正常通过 SLAAC 获取地址并配置 IPV6 默认网关,另一台 B 没有正确获取到默认网关(实际上也没有正确地从 SLAAC 配置本地地址,起初并没有关注这个点),经过对比两机 IPV6 相关 sysctl 参数,仅有一条 net.ipv6.conf.{iface}.forwarding 不同,A 没有允许 forwarding 而 B 默认允许。
为了搞清楚 forwarding 和 SLAAC 有什么关系,查看了 IPV6 自动配置相关比较重要的几个内核参数,得知:
net.ipv6.conf.{iface}.autoconf代表是否启用 SLAAC 配置地址,其默认值与net.ipv6.conf.{iface}.accept_ra_pinfo有关,若accept_ra_pinfo=1则此默认值也为1,反之亦然net.ipv6.conf.{iface}.accept_ra_pinfo代表是否从 RA 中接收前缀,其默认值与net.ipv6.conf.{iface}.accept_ra有关,若accept_ra=1则此默认值也为1,反之亦然net.ipv6.conf.{iface}.accept_ra当且仅当此值大于0表示接收 RA,接收 RA 时,本机才会发出 RS 并接收 RA,值为2时将忽略forwarding配置,永远接收 RAnet.ipv6.conf.{iface}.forwarding类似 IPV4 的 forwarding 属性,配过 NAT 应该就认识这个配置。此值为1表示启用 IPV6 转发,此时本机发出的 NDP 中将带有IsRouterflag ,内核开发者认为,启用 forwarding 代表这台主机具备路由器属性,且被转发包可能是 RA 报文,因此路由器原则上是不能接收外来 RA的。如果本机不是路由器则不应打开转发功能
和 RA 生效的部分细节配置还有不少,配置默认路由的 accept_ra_defrtr,配置MTU的 accept_ra_mtu 等不在此展开,详情可以从 https://sysctl-explorer.net/ 搜索,也可以直接在 https://www.kernel.org/doc/Documentation/networking/ip-sysctl.txt 中 CTRL+F。
因此,似乎只要将服务器 B 的 accept_ra 参数改为2即可圆满解决问题,然而事不如愿,于是问题进入了更深一些的排查。
排查:地址和默认路由从何而来?
我们虽然知道了上述内核参数会影响 SLAAC 的行为,但是具体对网络栈的操作是由如何执行的其实并不清楚,这个问题的直觉反应有:NetworkManager 等网络管理进程添加,或者是内核自行添加的,通过确认 A B 两机的系统环境 Ubuntu 18.04(内核 4.15)和 Debian 10(内核 4.19),此时的我认为两台机器都只通过 ifupdown 管理,检查 ifupdown 的目录没有发现 IPV6 相关的配置项,因此认为操作由内核完成(事实上内核确实有自己的 RA 实现),但是内核态的操作不方便查看和调试,于是需要找一个用户态程序进行收法包调试。
ndisc6 软件包提供了 rdisc6 命令(ndisc is for Neighbour DISCovery),可实现用户态构造 ICMPv6 Router Discovery 消息(一般情况下 NDP 消息都由内核处理),执行命令会导致内核立刻更新 RA 通告的前缀和路由状态,因此,理论上执行 rdisc6 <iface> 会立刻刷新该网卡接口上的 SLAAC 状态。也可以借助这个命令,配合 tcpdump 抓包进行 debug
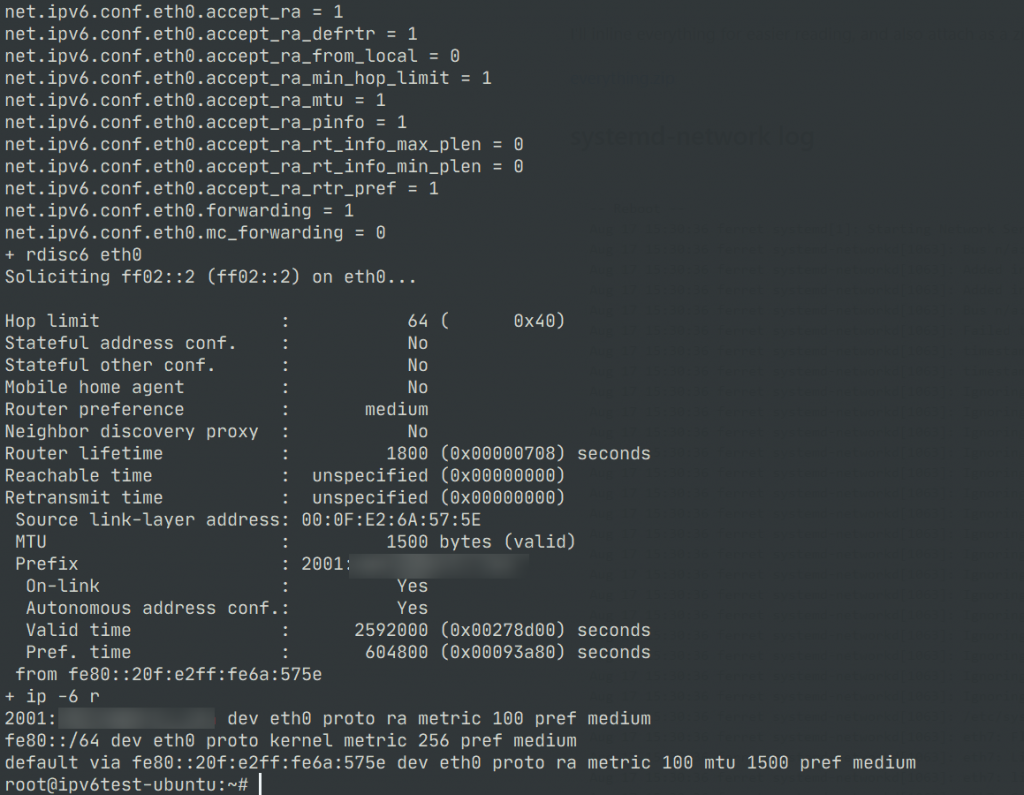
使用 tcpdump 捕获 RS 和 RS 的命令是 tcpdump -i any -vvvvn icmp6 and 'ip6[40] = 133 or ip6[40] = 134' 其中 133 和 134 是 RS 和 RA 在 ICMPv6 中定义的消息类型,通过在 B 机器抓包,确认了 rdisc6 运行时 RS 和 RA 报文的交互是正常的,但是内核在此后没有添加地址和路由信息,开始怀疑内核出现了 bug,也确实搜索到了一些疑似相同问题的报告 https://lists.debian.org/debian-user/2018/08/msg01113.html ,但是这个问题出现在 4.9 内核的 Debian,list 里没有实质性的证据是什么地方引入了这个 bug,且这个邮件没有看到更多 follow-up,并不是很能确定这个现象就是内核 bug 造成,4.9 到 4.15 有两年时间,这样的 bug 在内核中存续如此长时间有点不合情理。
在进一步排查和复盘中发现,修改 IPV6 的部分配置如 sysctl net.ipv6.conf.all.forwarding=0 时,所有网卡的 forwarding 属性都会被设为0,然而 autoconf 和 accept_ra 并不遵守这个行为, 在配置 sysctl net.ipv6.conf.all.accept_ra=0 后,eth0 的 accept_ra 值依旧可以为原值(可能是0,也可能是其他值),这意味着 net.ipv6.conf.all.accept_ra 这个参数是没有任何实际作用的。这个行为同样搜到了一些报告,https://bugs.launchpad.net/ubuntu/+source/linux/+bug/997605 疑似是一个持续了近十年了内核 bug(Linus: No, it’s a feature™),内核版本横跨 3.4~5.4 三个大版本,顿时让我觉得之前简直是过于乐观了,区区 4.9~4.15 算什么。这个问题的 work around 是确保所需的网卡接口上的配置是正确的,而不要试图使用 all,很无奈,这个问题虽然不是什么致命问题,居然能存在如此之久确实令人难以理解。
回到我们讨论的问题,翻查 shell 历史记录后发现,先前配置时正是因为使用 sysctl net.ipv6.conf.all.accept_ra=2 而没有对具体网卡接口进行配置,导致实际 accept_ra=2 没有被正确的配置到接口上。
内核之外:netplan 和 networkd 对 SLAAC 行为的影响
在梳理和复盘这些问题的过程中,我摸了一台新的 Ubuntu 18.04 虚拟机方便复现问题,此时发现新的虚拟机表现出了不一样的行为,我将内核参数配置为 forwarding=1accept_ra=1,理论上此时系统将忽略 RA,然而实际行为是系统仍然配置了 SLAAC 地址并添加了路由,进一步尝试修改 accept_ra_defrtr=0,理论上此时将不会从 RA 获取默认路由,然而这一配置也没有生效,在另一台全新安装的 Debian 10 4.19 内核上,一切行为是符合预期的。
我将 Ubuntu 虚拟机的内核版本升级到最新的 5.4 后,行为依旧,看起来先前把锅甩给内核版本的判断是有问题的,即使是内核的问题那也是 Ubuntu 和 Debian 之间内核编译参数的问题,然而这种可能性很小,应该把目光放回到用户空间程序来,一看进程列表发现 Ubuntu 有 netplan 且是默认启用 systemd-networkd 的(Debian 默认没有使用 netplan或 systemd-networkd),先前我判断系统中只有 ifupdown 管理网络错误、武断而愚蠢。
发现 netplan / systemd-networkd 也对这个问题存在影响,当卸载 netplan 后,Ubuntu 虚拟机的表现就变成了和 Debian 一样。netplan (包名 netplan.io,同官网域名) 是 C 社出品的一个网络配置渲染器,使用 yaml 格式的描述性配置生成实际的网络管理配置,可以和 systemd-networkd 或 NetworkManager 协同,由于 Ubuntu 的默认安装中包含 systemd-networkd 而没有 NetworkManager,因此可知实际对网络的操作由 systemd-networkd 进行。于是尝试清查 netplan 到底生成了什么配置导致了 systemd-networkd 的行为,但由于我个人一直在用 Debian+ifupdown 管理网络,对 systemd-networkd / NetworkManager 这些复杂的网络管理工具不太熟悉,调试起来很痛苦,于是直接查了一番 sysmted-networkd 的文档,发现了下面这段:
Takes a boolean. Controls IPv6 Router Advertisement (RA) reception support for the interface. If true, RAs are accepted; if false, RAs are ignored, independently of the local forwarding state.
···but note that systemd’s setting of 1 (i.e. true) corresponds to kernel’s setting of 2.
Note that kernel’s implementation of the IPv6 RA protocol is always disabled, regardless of this setting. If this option is enabled, a userspace implementation of the IPv6 RA protocol is used, and the kernel’s own implementation remains disabled, since systemd-networkd needs to know all details supplied in the advertisements, and these are not available from the kernel if the kernel’s own implementation is used.
—— https://systemd.network/systemd.network.html#IPv6AcceptRA=
翻译过来就是:systemd-networkd 为了做到完全了解系统的网络状态,屏蔽了内核的 RA 实现,且 networkd 的 IPv6AcceptRA=true 行为上等于内核的 accept_ra=2,无视本地 forwarding 设置的状态。
看完这段我内心充满了草泥马简直是天坑,屏蔽内核实现,默认行为还不一样,这也过于霸道了,不愧是你啊 systemd。
至此虚拟机上 Ubuntu 的行为也可以解释了,netplan 向 /run/systemd/network/ 生成了 systemd-networkd 格式的配置,导致 networkd 接管 eth0 后屏蔽了内核的 RA 实现,内核参数的修改不再生效,而卸载 netplan 后,networkctl 显示 eth0 unmanaged,说明 eth0 处于 ifupdown 和内核的管理下,此时行为符合预期。
一些后话
最初这个问题只是想了解一下为什么某服务器在一次重启后没有正确从 RA 获取到路由,由于不清楚具体系统在初始化网络的过程中的细节,也不熟悉 systemd unit 的调试,调试问题逐渐变成了对相关知识的查漏补缺,中途也得出过一些不太正确的结论,最后这个问题虽比较完美的解决,然而所花费的时间和精力已经远远超出了最初的预期。很多时候看起来“玄学”的问题来源于我们对工具的不够了解,求甚解很费时间,而最后得到的结论也不一定具有放之四海而皆准的价值,这导致我们很多时候会选择 dirty fix,比如这个问题其实当时完全可以通过一把梭手动添加静态路由分分钟 it works™,一念之差也许就没有本文了,也要感谢新冠肺炎,没有它可能也不会有这么闲的时间研究这个问题(笑)。
说点题外话,C 社很长一段时间来似乎都想转型为云计算服务提供商,他们造的轮子各种轮子都看起来像是为云环境设计,类似 cloud-init 和 netplan 都有使用 yaml 格式描述性的定义云计算资源和需要的配置(比如在我这次使用的 ubuntu-cloudimage 镜像中,cloud-init 代替了 debian-cloudimage 的 /etc/udev/rules.d/70-persistent-net.rules 持久化网卡接口名称,netplan 代替了 ifupdown 管理网卡,如果不是遇到 SLAAC 的问题其实它工作的还不错),试图对用户屏蔽下层具体的实现、具体执行资源配置的 provider 的配置文件格式,理念是好的,然而这些轮子没有成为云计算平台的主流工具,C 社又喜欢把这些东西都往 Ubuntu 里塞,给人以“夹带私货”的印象(其实红帽也不是什么省油的灯),做云服务工具反响平平,类似 maas.io 等试图做 on-prem 市场的服务也没掀起多大波纹。而早年做的一些基础系统工具更是起了个大早赶了个晚集, snap 野心勃勃妄图做跨发行版包管理然而使用不便且对社区不友好始终只有 C 社在自娱自乐,upstart 出师不利被 systemd 后来居上最终成为弃子,C 社在正确的做事思路上却一直做出来的东西差强人意,我对其的态度和评价可谓一言难尽,这些方轮子(或者说往系统里塞的私货)没少给我添麻烦,另一方面又比较可惜他们没有足够的实力把这些轮子捏的更圆一点,毕竟作为用户,需要警惕垄断对市场对社区的伤害,不是那么乐于看见开源领域红帽一家独大。
不管怎么说,这个问题让我比较系统的学习了一下 SLAAC 的相关配置,在 IPV6 尚未普及的 IDC 内部服务器管理遇不到这样的场景而缺少实践的机会,也算是填了一个很久以来一直半懂不懂的坑,感谢 jackyyf hexchain akw kaseiwang 等群友在排查问题中提供的帮助。
本文链接:https://www.starduster.me/2020/02/19/talk-about-slaac-on-linux-principle-configuration-and-behavior/
本站基于 Creactive Commons BY-NC-SA 4.0 License 允许并欢迎您在注明来源和非商业使用前提下自由地对本文进行复制、分享或基于本文进行创作。
请注意:受限于笔者水平,本站内容可能存在主观臆断或事实错误,文中信息也可能因时间推移而不再准确,在此提醒读者结合自身判断谨慎地采纳。
Permalink
我就想查一下 IPv6 的资料,没想到在这里还能撞上邪恶的 systemd
Permalink
写的很详细,太感谢了!我正在设置PVE host的IPV6,但是无论如何都会出现Router lifetime耗尽的时候无法正常刷新,目前的解决方法只能定时使用文章中提到的rdisc6刷新配置。
Permalink
写的好详细,太棒了!
Permalink
为什么生成的默认路由都是fe80开头的保留地址呢?
Permalink
这时候IPV6会通过NDP在本地子网自动找网关
Permalink
我也遇到了一样的问题,服务器上启用了
net.ipv6.conf.all.forwarding=1网卡能通过 RA 获得 IPv6 地址,但是没有路由信息,导致 IPv6 网络不通。你的这篇文章刚好解决了我的问题,非常感谢。
Permalink
Permalink
Permalink
IPv6动态地址分配机制详解 https://packetmania.github.io/2020/12/01/IPv6-Addressing/
Permalink
本文只是我的一次实际问题的解决过程并没有打算写成百科一样的reference,加之我的工作没有太多接触过交换机的配置所以只从Linux主机角度讨论,不过依然非常感谢您的补充。