
TL,DR:
Broadwell 的 Cluster on die 和 Skylake 的 sub-NUMA cluster 设置会导致高核心 CPU 显示为两个 NUMA 节点,相关设置会影响缓存命中、延迟和内存访问延迟
Index
0,起因
1,简述架构的改进
2,Broadwell 上的 Snooping 和 COD
3,Skylake 和 SNC
4,其他的一些改进
起因:
某台机器(已知是双路)发现了四个 NUMA 节点:
numactl也显示出了程序的不同亲和性,
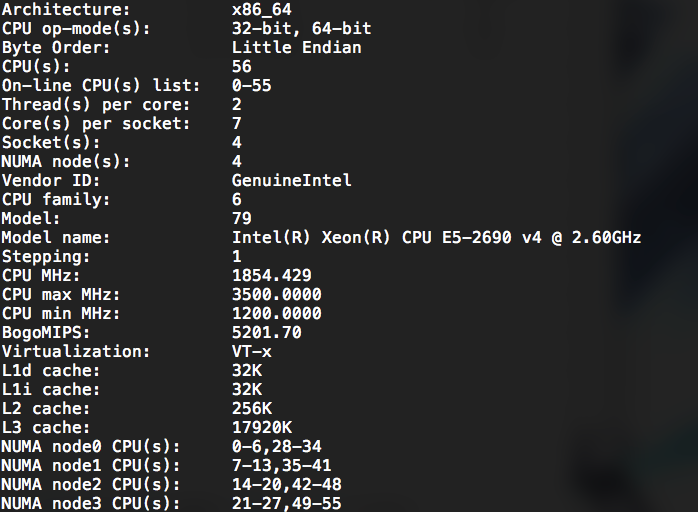
然而根据 Intel Ark ,2690 v4 最大支持两路,且每路为 35M L3,核心数和 L3 cache 显示的数量都恰好是 ark 的一半,因此对这个问题进行了一点调研,发现 Xeon Scalable 相比 Xeon E5v4 确实有比较大的改变不是挤牙膏,借此机会顺便深入了解了一些服务器 CPU 的架构,故有本文。
文中可能用到的几个缩写:Ivy Bridge 缩写为 IVB,Haswell 缩写为 HSW,Broadwell 缩写为 BDW,Skylake 缩写为 SKX,LLC 等同于 L3, MLC 等同于 L2
简述:Haswell/Broadwell 的双环结构和 Skylake 的 mesh 结构
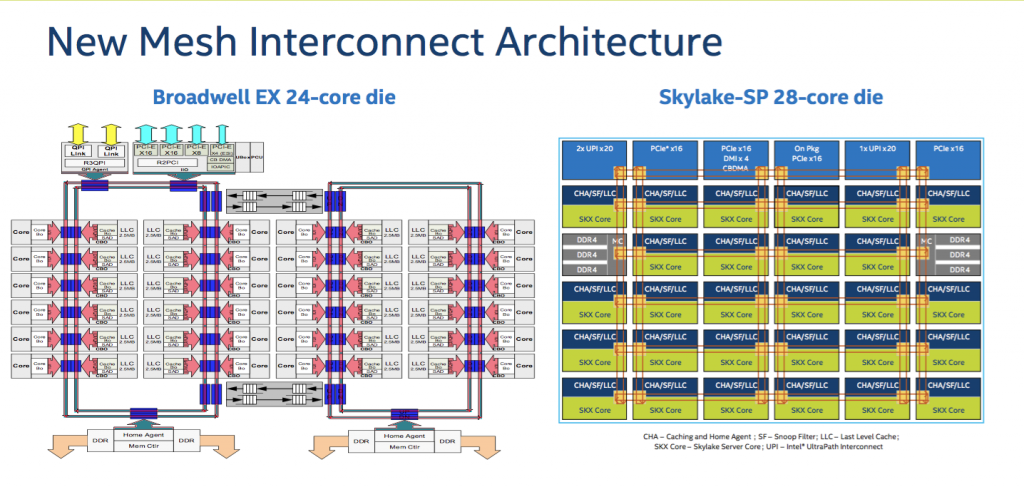
要解释这个疑问,需要先讨论服务器上高核数 CPU 的设计,简要的说,为了在一块 CPU 里塞进越来越多的核心数,Intel 的多核 CPU 引入了 ring bus 的设计,核心、LLC、QPI 控制器分布于环上,内存控制器和 QPI 总线分布在环的两端,然而这样的结构随着核心的增加,延迟也会增加,于是从 Haswell 开始,高核心数的服务器 CPU 开始使用双环+双内存控制器的架构,在 LCC 中是单环, MCC 中是一个完整环和一个半环,HCC 中则是两个完整的环,半环和完整的环都带有一个独立的内存控制器。
ring bus 架构的缺点很明显,即便是分成了两个环,依旧会有核心越多延迟越大的问题,且跨环访问时会增加一个额外的 CPU cycle 的延迟,所以 Broadwell 算是把 ring bus 续命做到了极致最多也只塞到了22个核心,为了塞进更多的核心数、更大的内存带宽,Intel 把 Xeon Phi 上最早出现过的 mesh 架构搬到了 Skylake 上, mesh 架构最多六行六列,其中一行被 UPI 和 PCI 控制器占据,另有两个位置是内存控制器,故最多塞进(6*6-6-2=28)个核心,同时还把 Cache 控制器、I/O 控制器等分布到了各个核心之间,新的控制器称为 CHA,这个 CHA 同时还提供了不同核心之间寻路的路由功能。很直观的可以发现,由于 mesh 结构避免了顺着环进行顺序访问的问题,核心-缓存延迟和核心-内存延迟会降低;除此之外,I/O 操作的初始化延迟也会改善。
| 代号 | LCC | MCC | HCC | XCC |
|---|---|---|---|---|
| BDW | < 10 core | 10-14 core | 16-22 core | N/A |
| SKX | < 10 core | N/A | 12-18 core | 20-28 core |
LCC=low core count, MCC=medium, HCC=high, XCC=extreme
Snooping 和 Cluster on die
从 Broadwell 的架构上很容易理解为什么会把一个 CPU 识别为两个 NUMA 节点——因为不同 ring 间的访问确实存在延迟上的差别,但是另一方面要注意,ring 间访问的速度仍然是片内 I/O,要比走 QPI 进行跨 socket 访问要快很多。实际上,这个特性是可以通过 BIOS 进行配置的,在 Broadwell 中,这一特性通过 snooping 策略来配置。
先了解一下什么是 snooping:
在分布式共享存储处理机(Distributed shared memory, aka. DSM)中需要维护缓存一致性(Cache coherence),为保持缓存一致性有两种策略,snooping 或者 directory-based(译作“侦听”和“基于目录”)
简单的讲,现代 CPU 具有多个核心,每个核心具有独占的一级缓存和共享的末级缓存(Last Level Cache, aka. L3 Cache),当有多个核心的缓存中存在同一个数据库的副本,他们都向 LLC 回写数据时,就存在数据冲突的可能。
- 为解决这一问题,snoop 策略采取了简单粗暴的总线广播方式,每个缓存控制器管理自有缓存块的状态并通过总线同步。
- 而基于目录的一致性则是使用目录来记录全局缓存的状态,一致性消息通过一个目录结构进行转发。
由于 snooping 使用了广播会占用总线带宽,一般认为 snooping 扩展性不如 directory-based,但是在带宽足够的前提下,snooping 会更快。
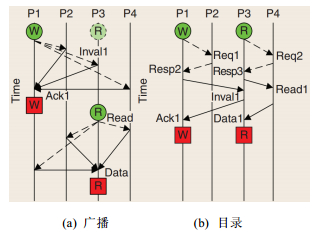
Broadwell 支持四种 snoop 模式,其中一种 Home Snoop with Directory and Opportunistic Snoop Broadcast (HS with DIR + OSB):从 IVB 继承而来, 另外三种 Early Snoop (ES), Home Snoop (HS), and Cluster on Die Mode (COD). 从 HSW 继承而来:
- COD:逻辑上分为核数和 LLC 各为一半的两个 cluster,被操作系统当做两个 NUMA 节点,snoop 请求将会被分为必须发送的和不必须发送的,适用于 NUMA 优化程序以实现最低的内存延迟和最高的近端内存带宽
- ES:snoop 操作由 cache agent 控制且必定发送,适用于对缓存延迟要求越低越好的程序应用,包括内存延迟和跨 socket 缓存延迟
- HS:snoop 操作由 home agent 控制且必定发送,适用于对近端和远端内存带宽都敏感的 NUMA 应用
- HS with DIR+OSB:Broadwell 默认 snoop mode,snoop 操作由 home agent 发起,且有一个目录用于判断 snoop 操作是否必须发送
再来一张 wikichip 的性能对比(数据源其实来自 Intel 官方的说明,不过这个表样式更便于观看):
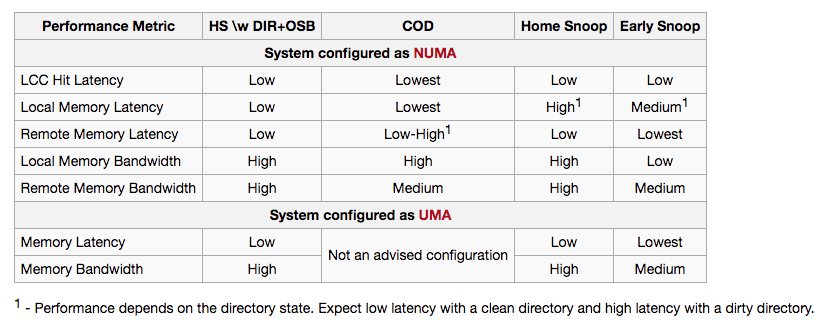
至于性能具体如何,参见 Intel 的实际测试:
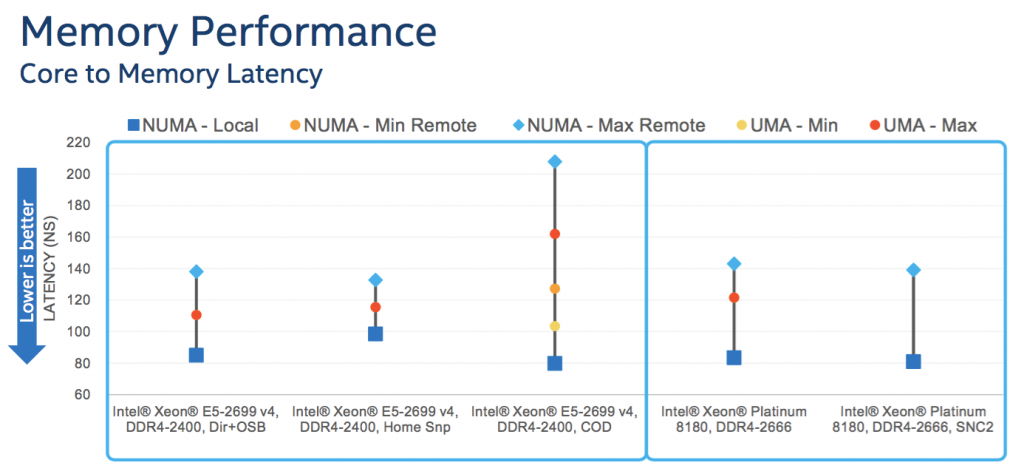
另外有联想在 SR650 上的测试:
From this graph, it can be seen that Cluster-on-Die (COD) memory mode with the “Performance” System Profile setting performs 2 to 4 % better than other BIOS profile combinations across all Broadwell processors. The Cluster-on-die (COD) is only supported on processors that have two memory controllers per processor, i.e. 12 or more cores.
至此,文首的疑问得到了解释,主板 BIOS 开启了 COD 模式导致一个 CPU 被划分成了两个 NUMA 节点,至于是否要保持这个特性的开启,应根据应用场景决定。
从 COD 到 SNC
在 Skylake CPU 中,也有类似的一个 CPU 识别为两个 NUMA 的现象,但是原因并不一致:
- 如前文所述,snoop 扩展性不如 directory-based
- 并且,由于 Skylake 的对 L3 缓存的管理策略发生了一些改变(改为了 non-inclusive LLC,在稍后进行详细介绍),导致 L3 cache 里不再一定包含 L2 数据,一次有效的 snoop 操作的平均延迟可能会增加(取决于数据具体存放的位置)
- 同时,由于内存带宽的大幅提高,如果大量不必要的 snoop 请求被发送到远端 socket 的 CPU 则 UPI 带宽将捉襟见肘
综合以上几个原因,Skylake 只有一种一致性策略:directory-base coherency,但是部分特性如 OSB (Opportunistic Snoop Broadcast)会被保留。
架构上,Skylake 也没有 home agent 和 cache agent 的区别而是合并为 cache home agent (CHA),但是由于核心较多时,mesh 结构即使是取最短路线也有可能跨过整个 die 而导致延迟较大,因此 Intel 为 Skylake 设计了 sub numa cluster (SNC),将核心、CHA 和 LLC 单元分配到物理距离较近的内存控制器上:
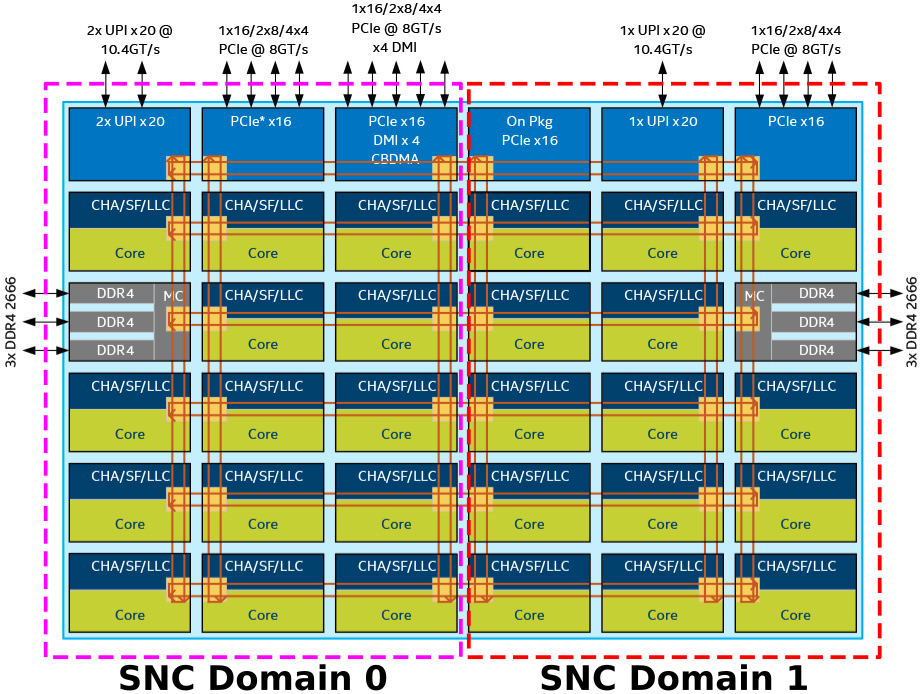
总结起来,即:
Broadwell 和 Skylake 都能体现“单 socket 显示两个 NUMA 节点”的特性,但是其实现和配置方式是不一样的
再来看看 sub numa cluster 对性能的改进在哪里:
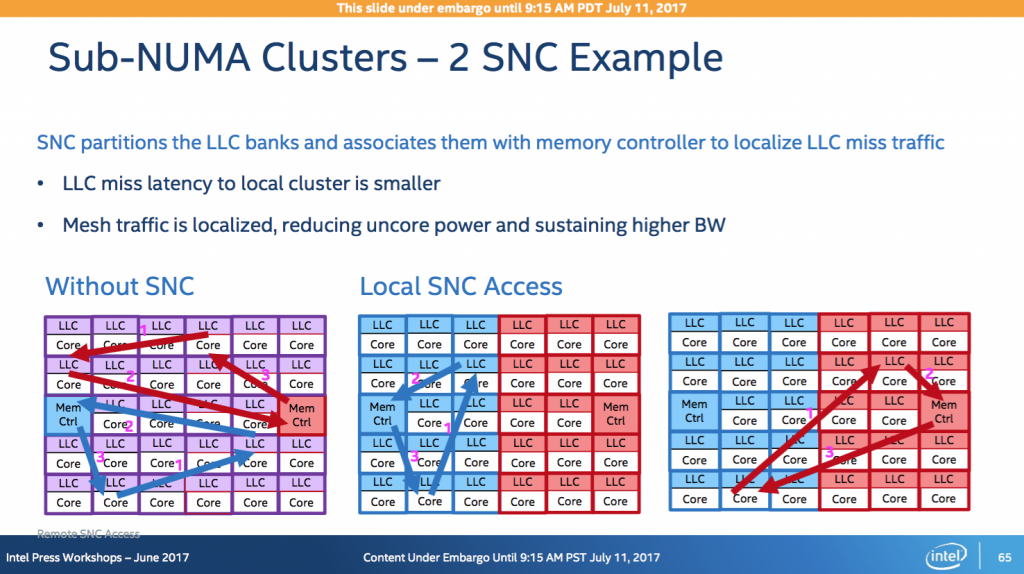
由于 SNC 的划分,核心在 L3 cache miss 的时候会从更近一侧的内存控制器去访问内存,可以期望 SNC 开启时有更低的平均内存访问延迟,实际测试也证明了这点:
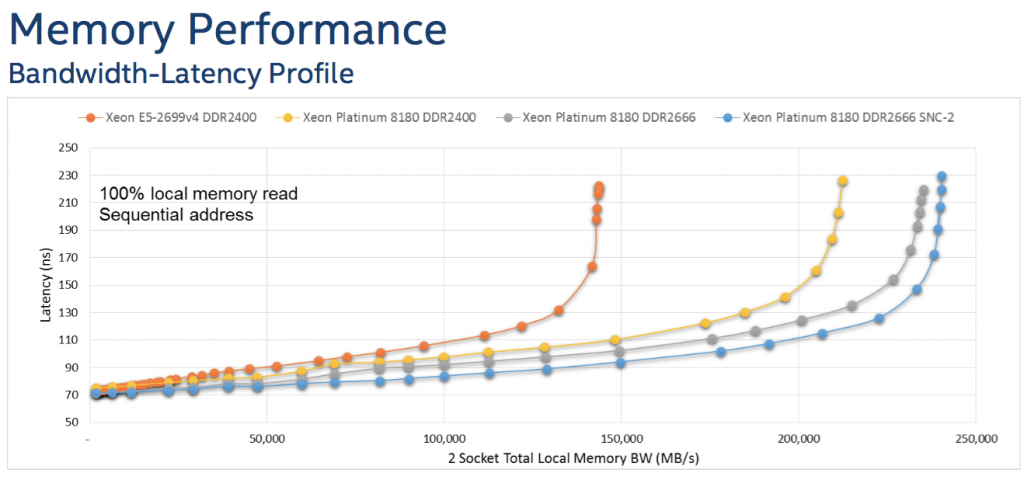
如图所示,在内存压力测试中,开启 SNC 的 Skylake 处理器有更高的极限带宽,而且在相同的吞吐下具有更低的访问延迟
其他一些改进
再来谈谈 Broadwell 到 Skylake 的其他改进,至少对于服务器端来说改进是比较大的
缓存分级策略
介绍一下什么是缓存分级策略,先前提到过的 inclusive & non-inclusive 是什么意思,简单的讲:
- inclusive 策略的核心是 cache miss 的时候将数据同时载入 L1 和 L2,而退化时只从 L1 中去除,因此,L2 始终包含 L1 的数据
- exclusive 策略的核心是 cache miss 的时候仅载入 L1,因此,L2 仅可能是 L1 退化下来的数据,但是 L2 和 L1 的数据是不同的
- NINE 策略则是 cache miss 的时候同时载入 L1L2,但是 L1L2 相对独立的进行退化
对于现代 CPU,此处的 L1 L2 实际应为 L2 L3
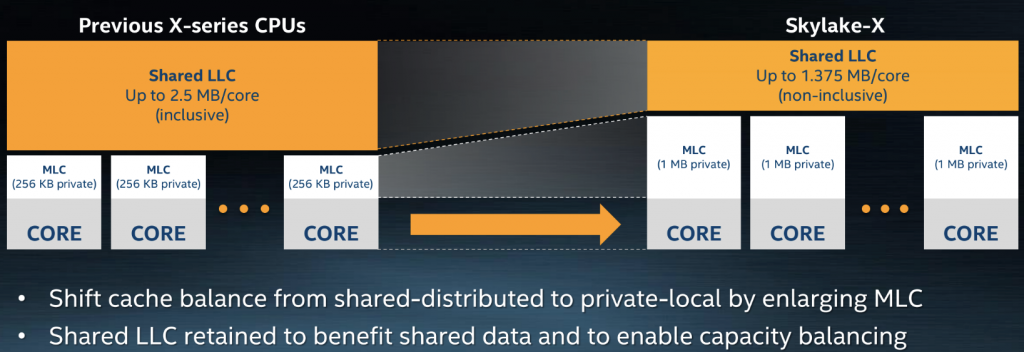
Skylake 的 L3 缓存策略变成了 Non-inclusive(根据 Intel 的描述,cache miss 的时候会将数据从主存放入 L2,退化时放入 L3,看起来更像是 Wiki 描述中的 exclusive 策略,特别的,跨核心访问的数据会被存到发起请求的核心的 L3 中),因此 L3 减小,L2 增加,这么做的好处是:
- 显然,MLC 命中率会增加,因此有效内存访问的延迟会下降(根据 Intel 的说法,相比 Broadwell L3 miss 率没有增加)
- 因此 LLC 的需求下降,对 mesh 中其他核心的访问频率也会下降(由于访问频次下降,虽然每次访问 L3 的延迟变大,Skylake 的平均 L3 访问延迟反而比 Broadwell 略低)
- 因此,对整个 CPU 来说,缓存效率会上升
- 另外,开启 SNC 会提高整体 L3 效率
但是 non-inclusive 的 LLC 导致了一个问题:在 L2 中的数据不一定在 L3 中,因此 Skylake 额外使用了 snoop filter 记录数据的流向,为了避免这一问题带来的影响,Skylake 中不再以 L3 为 primary cache,而是以 L2 为 primary,L3 为 overflow cache(这一改变被称为 shared-distributed to private-local)。

Intel 指出,在新的缓存策略下,只占用一个 CPU 核心的单进程模型的应用看到的可用缓存空间应为(L2 per core + a portion of L3 per core),可用缓存空间和上代 CPU 平台上大致持平,但是对于多进程应用,可用缓存空间可能和在上代 CPU 平台运行时不一样,Intel 提醒开发者对此进行优化。
AVX512 和 AVX 频率策略改进
AVX512 是 AVX 指令集的演进,支持 512bit 位宽,在深度学习、密码学计算等领域应用前景广阔,根据 Intel 的官方数据,Xeon Scalable 比前代 CPU 在 OpenSSL 计算上有约2到3倍的性能提升,不过我没有成功复现这个数据。
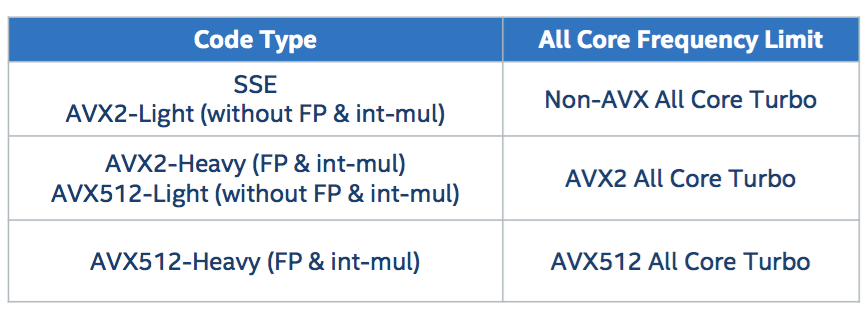
AVX 降频问题在 Skylake 中也得到了一定的改善,主要体现在少数核心运行 AVX 任务时不再会导致全核降频,且具有更灵活的降频等级,在执行低复杂度指令(非 AVX512 乘法集等)时,依然使用相对较高的主频运行:
RAM
内存通道数从4提高到了6,同时支持的频率提高到了2666,因此内存带宽大致有超过60%的提高
UPI
Skylake 中,片间互联总线不再是 QPI 而是 UPI,总线速度从 9GT 左右提高到了10GT 左右,最重要的是数量从2变成了3
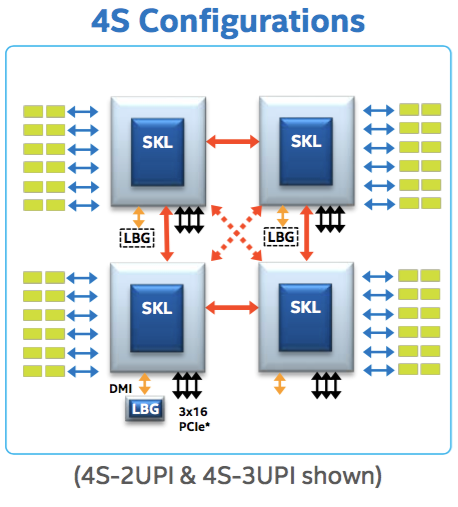
最直观的一个好处就是,四路 CPU 之间的 NUMA 可以两两等距,不再有先前 2QPI 时对角线问题,虚线表示的即是 Skylake 多出来的一条 UPI 总线带来的互联
参考和致谢
- http://www.jos.org.cn/html/2017/4/5245.htm 片上多核处理器Cache一致性协议优化研究综述
- https://en.wikichip.org/wiki/intel/microarchitectures/broadwell_(client) wikichip BDW
- https://en.wikichip.org/wiki/intel/microarchitectures/skylake_(server)#Sub-NUMA_Clustering wikichip SKX
- https://doc.itc.rwth-aachen.de/download/attachments/28344675/04.Aixcelerate_2016-BDW_and_KNL.pdf 那个谜之图的出处(phi 中先出现的 mesh 架构,但是 phi 中的 SNC 实际上是四个 core 组成一个 sub numa 暴露给操作系统)
- https://hpc-forge.cineca.it/files/ScuolaCalcoloParallelo_WebDAV/public/anno-2017/26th_Summer_School_on_Parallel_Computing/Bologna/SCP-KNL.pdf 另一个奇怪的图
- https://en.wikichip.org/wiki/File:intel_xeon_scalable_processor_architecture_deep_dive.pdf Intel xeon scalable processor architecture deep dive
- https://software.intel.com/en-us/articles/intel-xeon-processor-e5-2600-v4-product-family-technical-overview broadwell overview,主要看看 Section Snoop Modes
- https://software.intel.com/en-us/articles/intel-xeon-processor-scalable-family-technical-overview skylake overview
- https://lenovopress.com/lp0752.pdf 联想的 SKX 性能测试
- http://en.community.dell.com/techcenter/high-performance-computing/b/general_hpc/archive/2017/08/21/performance-study-of-four-socket-poweredge-r940-server-with-intel-skylake-processors dell 的 skylake 开关 SNC 性能测试
- https://sp.ts.fujitsu.com/dmsp/Publications/public/wp-broadwell-bios-settings-primergy-ww-en.pdf 富士通的 SKX 平台 BIOS 调优指南
- https://blog.cloudflare.com/on-the-dangers-of-intels-frequency-scaling/ cloudflare 关于 AVX 降频情况的调研
另外感谢 jackyyf 在本次调研中提供的帮助和教育
本文链接:https://www.starduster.me/2018/05/18/talk-about-evolution-from-broadwell-to-skylake/
本站基于 Creactive Commons BY-NC-SA 4.0 License 允许并欢迎您在注明来源和非商业使用前提下自由地对本文进行复制、分享或基于本文进行创作。
请注意:受限于笔者水平,本站内容可能存在主观臆断或事实错误,文中信息也可能因时间推移而不再准确,在此提醒读者结合自身判断谨慎地采纳。
Permalink
厉害,一文给我讲明白了
Permalink
Permalink
无意间搜索到这篇文章 ,一字一句都写得很到位 分析得很透切。
Permalink
高深莫测,膜拜